Ask most people what blood test AI does and they picture a chatbot that reads a lab report and talks about it. That conversational layer is the last five percent of the work. The first ninety-five percent is unglamorous engineering: turning a messy scanned document into structured, coded, unit-normalized data that a clinical-rules engine can reason over without hallucinating. This article opens the hood on the whole pipeline the way we actually built it, so you can judge any ai blood test tool on its architecture rather than its marketing.
Who wrote this
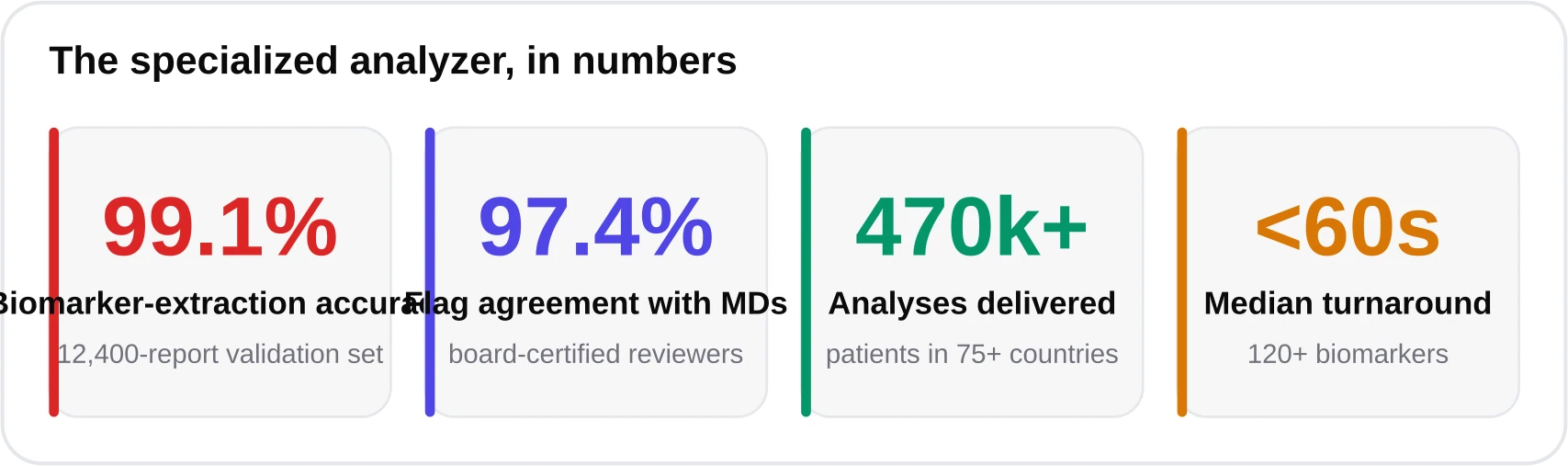
I lead engineering at blood-test.life (ex-Google Cloud Healthcare). Our analyzer is powered by the Kantesti AI infrastructure and has delivered 470,000+ analyses across 75+ countries. This piece was medically reviewed by Dr. Sophie Laurent, MD, MPH (Hematology, Penn). Numbers cited are from our June 2026 validation set of 12,400 anonymized reports.
What blood test AI actually is
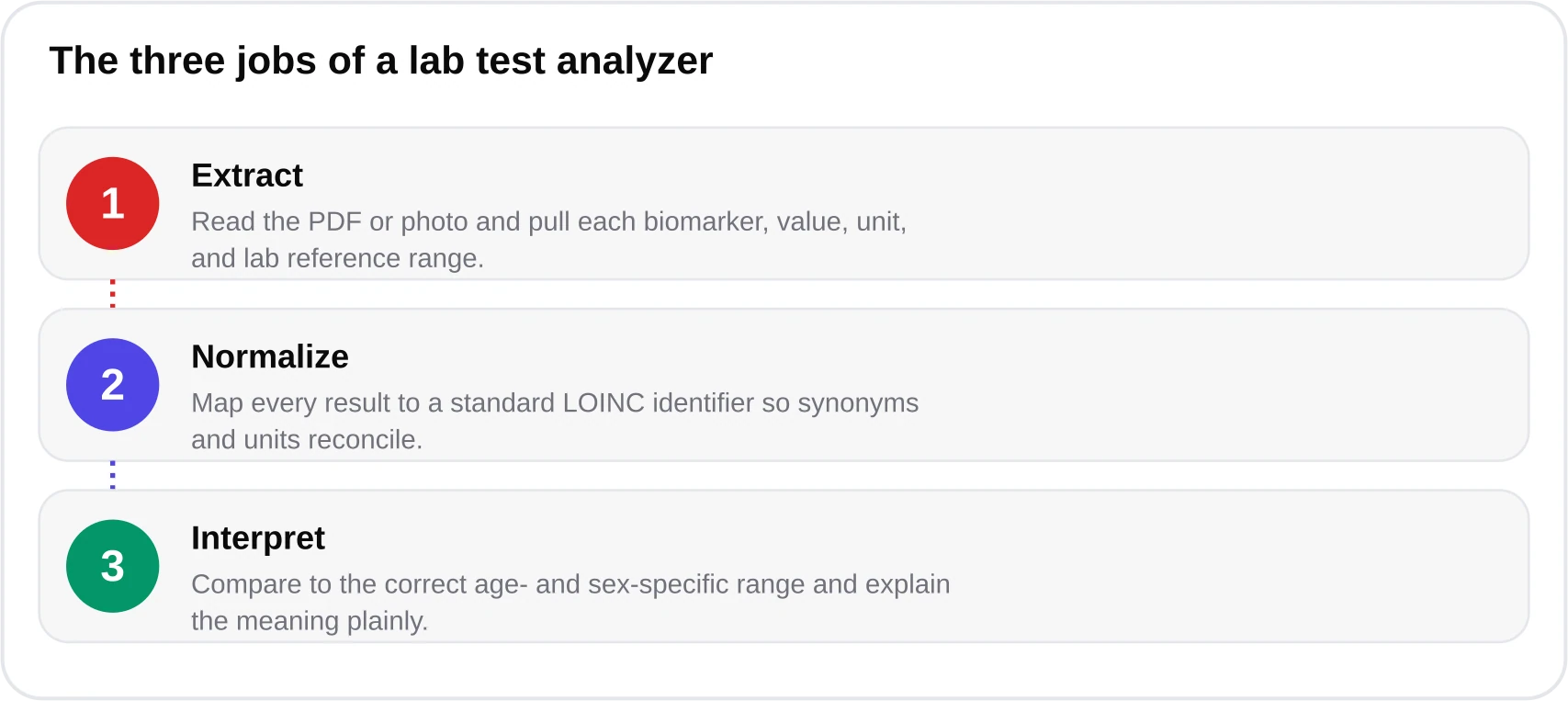
A useful mental model: a serious blood ai system is a five-stage assembly line, not a single neural network. Stage one parses the document into text and layout. Stage two normalizes each result — harmonizing units and attaching a standard identifier such as a LOINC code. Stage three interprets each value against the correct reference interval for the patient's age and sex. Stage four applies a clinical-rules engine to flag patterns and escalate anything urgent. Only stage five, the narrative, uses a language model to write in plain English — and even that is tightly constrained by the structured facts produced upstream.

This separation matters because the failure modes of each stage are different. A parser fails by misreading a decimal point. A language model fails by inventing a plausible-sounding threshold. Keeping them apart means a mistake in one stage does not silently corrupt the others, and each can be validated independently. If you want the consumer-facing version of this walkthrough, see our guide to the AI blood test analyzer.

Step 1: Parsing the document
Lab reports are deceptively hostile to machines. A single national lab may emit a dozen PDF templates; hospitals export portal summaries with nested tables; patients photograph a printout at an angle under kitchen lighting. Parsing has to survive all of it. Our approach uses a template library first and a vision fallback second. When a document matches a known layout — say, a specific Quest or LabCorp template — we extract fields by their known coordinates and table structure, which is fast and near-perfect. When it does not match, we fall back to a vision-language model that reads the image the way a person would, locating the analyte column, the value, the units, and the printed reference range.
OCR is where naive tools quietly break. The classic pitfalls are all clinically dangerous: a comma decimal separator (European reports write 4,5 for 4.5), a misread 7 as 1, an O versus 0, thousands separators that turn a platelet count of 250,000 into 250, and superscript footnote markers glued onto a value. A parser that treats OCR text as ground truth will confidently report a hemoglobin of 1.4 g/dL. We guard against this with sanity ranges per analyte, cross-checks against the printed reference interval, and a confidence score that routes low-confidence extractions to the vision model for a second read.

The combined strategy is why our extraction accuracy holds at 99.1% across formats rather than only on pristine PDFs. It is also why we insist on structured confidence: the system knows what it is unsure about and says so, instead of guessing. You can see the extraction layer in action in our sample report, and a broader tour lives in the lab test analyzer explainer.
Step 2: Units and LOINC mapping
Once values are extracted, they are still not comparable. The same analyte appears under different names, different units, and different scales. Glucose might read 100 mg/dL on a US report and 5.6 mmol/L on a Canadian one — identical physiology, different numbers. Hemoglobin is g/dL in the US and g/L elsewhere. Normalization converts every value into a canonical unit and, critically, attaches a LOINC code — the international standard identifier maintained by the Regenstrief Institute — so that "Glucose, fasting," "FBS," and "Fasting blood sugar" all resolve to the same concept.

Unit conversion sounds trivial and is not, because the conversion factor depends on the analyte's molar mass. Total cholesterol converts mg/dL to mmol/L by dividing by 38.67; glucose by 18.02; creatinine by 88.4. Hard-coding one factor for everything is a common bug that produces silently wrong values. We store per-analyte conversion metadata alongside the LOINC map, and the IFCC (International Federation of Clinical Chemistry) harmonization work is the reference for standardizing these across labs. Getting this layer right is what lets us serve reports in 75+ languages while keeping the numbers coherent.
Why LOINC is the backbone
Without a standard code, an AI cannot know that two differently named rows are the same test — or that a value belongs to a specific reference interval. LOINC turns free-text lab names into stable identifiers, which is the prerequisite for every downstream clinical rule.
Step 3: Reference intervals and the 5% problem
Here is the single most misunderstood fact in lab medicine: a reference interval is not a health target. It is, by construction, the central 95% of results in a reference population of apparently healthy people. That means roughly 5% of perfectly healthy individuals fall outside any given range — about 2.5% below and 2.5% above — purely by statistical definition. Order twenty independent tests on a healthy person and, on average, one will flag "abnormal" for no clinical reason at all. A good ai blood test tool teaches this rather than alarming you with it.

Reference intervals also depend heavily on who you are. A hemoglobin that is normal for an adult man is low for a menstruating woman; alkaline phosphatase is sky-high in growing children and falls with age; creatinine tracks muscle mass. This is why partitioning matters. We use age- and sex-specific partitions grounded in the CALIPER (Canadian Laboratory Initiative on Pediatric Reference Intervals) and NORIP (Nordic Reference Interval Project) studies, plus CDC 2024 population data. Applying an adult range to a twelve-year-old's report is a classic way AI tools generate false alarms.

Clinical thresholds are a distinct concept from reference intervals, and the AI must not conflate them. Some cutoffs come from guideline bodies, not from a population's central 95%. HbA1c of 5.7–6.4% defines prediabetes and 6.5% or higher defines diabetes per the American Diabetes Association Standards of Care. LDL targets are risk-stratified by AHA/ACC and ESC: under 100 mg/dL generally, under 70 for high-risk patients, and under 55 with established cardiovascular disease. Vitamin D deficiency is commonly defined below 20 ng/mL. TSH sits roughly 0.4–4.0 mIU/L per American Thyroid Association guidance. These are fixed, sourced, and hard-coded — never generated by the language model. Dive deeper in our HbA1c explainer and lipid panel guide.

Step 4: Rules engine vs. language model
This is the architectural decision that separates a medical-grade blood ai system from a chatbot wrapper. The interpretation itself — is this value low, high, critical; does this combination of results suggest a recognizable pattern — is done by a deterministic clinical-rules engine, not by a neural network. Rules are transparent, testable, and reproducible. Given the same input, they always produce the same output, and every flag traces back to an explicit, reviewable condition written with our medical advisors.
The language model should never be the thing that decides whether a value is dangerous. That decision has to be deterministic, sourced, and auditable — otherwise you cannot stand behind it clinically.
— Dr. Sophie Laurent, MD, MPH, Hematology, Penn
A concrete example: iron-deficiency anemia is not a single flagged number but a pattern — low hemoglobin, low ferritin, low transferrin saturation, often with elevated red cell distribution width. A rules engine encodes that pattern explicitly and can surface "these results together are consistent with iron deficiency, discuss with your clinician," while a raw LLM might latch onto one value and miss the constellation. We walk through exactly this case in our iron-deficiency anemia guide. Critical values — a potassium that could stop a heart, a wildly abnormal glucose — are escalated by hard rules with the highest priority, never left to a probabilistic model.


Step 5: Constrained narrative generation
Only now does the language model earn its keep. Its job is narrow: take the structured facts — this analyte, this value, this flag, this reference interval, this guideline context — and write clear, calm, plain-language explanation. This is constrained generation: the model is not free to invent numbers, thresholds, or diagnoses. It receives the interpreted results as fixed inputs and produces prose around them. Our stack uses the health-llm-v4.7 model for wording, wrapped by the deterministic rules engine that supplies every clinical fact. The relationship is deliberate — fluency from the model, truth from the engine.
Guardrails at this stage include refusing to state a diagnosis, always pairing an abnormal flag with "discuss with your clinician," and never recommending a specific drug or dose. Native medical QA runs in 15 languages, with automated checks that the narrative's stated values match the structured record exactly — a mismatch blocks delivery. If you want to see how this compares to pasting results into a general chatbot, we cover it head-to-head in AI interpretation vs. ChatGPT.

What training means, and your data
"Training" is thrown around loosely, so let me be precise. Training is the process of adjusting a model's internal parameters by showing it many examples. A model can be trained once and then used ("inference") on new inputs without further learning. The crucial point for privacy: using a trained model to read your report does not require training on your report. These are separate operations. At blood-test.life, the core models are trained on curated, licensed, and de-identified reference material — not on consumer uploads.
Our data promise
We never train on user data. Uploaded files are processed to generate your report and then deleted after delivery. We are HIPAA-aligned and GDPR/CCPA compliant. Your lab report is an input to inference, never a training example.
This is a design choice with real cost — it would be cheaper to harvest uploads — but it is the only posture we consider defensible for health data. It also removes a whole class of risk: a model that never memorizes your results cannot leak them. The full technical detail lives in our methodology page, and the plain-language version is in how it works.

Honest limits of the technology
No credible blood test ai should oversell itself, so here is the honest boundary. Our analyzer is an educational tool, not a medical device, and it does not diagnose. It contextualizes your numbers so you walk into an appointment informed; it does not replace the clinician who knows your history, medications, and symptoms. A 97.4% flag-agreement with physicians is strong, but it is not 100%, and the 2.6% gap is exactly why a human stays in the loop. If you have symptoms — chest pain, severe fatigue, bleeding — seek care regardless of what any tool says.
There are also things a snapshot cannot capture. Trends over time often matter more than a single value; a result at the edge of a range on one draw may be meaningless variation. Pre-analytic factors — fasting status, hydration, recent exercise, time of day, hemolysis in the sample — shift results in ways no software can see from a PDF. Bodies like the USPSTF, NICE, and Cochrane repeatedly emphasize that a test result is one input among many, interpreted in clinical context. We build that humility into every report, and it is why the narrative always ends by pointing you back to a professional.

That, end to end, is how machine learning actually reads your labs in 2026: not one magic model, but a disciplined pipeline where a language model does the talking and a deterministic engine does the deciding. If you want to try it on your own results, the analyzer is free during the 2026 public beta at features, with pricing details on our pricing page. Read your report with a clear head, then take it to someone who can act on it with you.
Frequently asked questions
Does blood test AI diagnose disease?
No. A responsible blood test AI, including blood-test.life, is an educational tool that contextualizes your numbers against reference intervals and guidelines. It does not diagnose, and it is not a medical device. Abnormal flags should always be discussed with a clinician who knows your history and symptoms.
Why did the AI flag a value as abnormal when I feel fine?
Reference intervals are defined as the central 95% of a healthy population, so about 5% of perfectly healthy people fall outside any given range purely by statistics. A single edge-of-range value on one draw is often normal variation. Trends over time and clinical context matter more than one number.
How accurate is the extraction from my lab PDF?
On our June 2026 validation set of 12,400 anonymized reports, biomarker-extraction accuracy was 99.1% and flag agreement with board-certified physicians was 97.4%. Accuracy is highest on clean PDFs; a vision-model fallback handles phone photos and scanned faxes.
Does blood-test.life train its AI on my uploaded results?
No. Using a trained model to read your report (inference) is separate from training. Our core models are trained on curated, de-identified reference material, never on consumer uploads. Your file is processed to generate the report and then deleted after delivery. We are HIPAA-aligned and GDPR/CCPA compliant.
How is this different from pasting my results into a general chatbot?
A general chatbot generates fluent text but can invent thresholds, miss age/sex partitioning, and lacks a deterministic rules engine or LOINC mapping. Our pipeline fixes every clinical fact with an auditable rules engine and only uses the language model for wording, constrained by those facts.
What is LOINC and why does it matter?
LOINC is an international standard code, maintained by the Regenstrief Institute, that gives each lab test a stable identifier. It lets the AI recognize that differently named rows — 'Glucose, fasting,' 'FBS,' 'Fasting blood sugar' — are the same test, which is a prerequisite for correct unit conversion and reference-interval matching.
References & sources
- LOINC — Regenstrief Institute (standard lab identifiers) — Regenstrief Institute
- American Diabetes Association — Standards of Care (HbA1c thresholds) — ADA
- ACC/AHA cholesterol and cardiovascular risk guidelines (LDL targets) — American College of Cardiology
- ESC/EAS dyslipidemia guidelines — European Society of Cardiology
- CDC — population health and laboratory reference data — Centers for Disease Control and Prevention
- USPSTF — evidence-based screening recommendations — U.S. Preventive Services Task Force
- CALIPER pediatric reference interval study — CALIPER Project
- NORIP Nordic Reference Interval Project — NORIP
Medical disclaimer
This article is informational and educational only and is not a substitute for professional medical advice, diagnosis, or treatment. blood-test.life is not a medical device. Always consult your physician or a qualified health provider about your results. Read our full medical disclaimer.